報導/盧履彥、房翠瑩
攝影/林郁靜、盧履彥
美國雪城大學教授秦健駐點中研院一週,開展知識組織系列講座,為聽眾上了一堂紮實的基礎課。本中心召集人陳熙遠主持「本體論的基本原理」專題講座。本中心執行秘書陳淑君(右)主持「本體論的設計方法」專題講座,其為促成本次學術交流活動的重要推手。出席者聚精會神聆聽秦健的講解與分享。國立臺灣歷史博物館數位創新中心研究人員許美雲(右一)向秦健請教,如何將資料庫打造為知識庫。秦健主講「開放科學與開放資料:圖檔領域的契機」專題講座。(圖片提供/國立臺灣大學圖書資訊學系)秦健、陳淑君(站者)與臺大學生就如何將研究資料提升為「開放科學」,展開討論交流。(圖片提供/國立臺灣大學圖書資訊學系)陳淑君(左五起)、秦健與「清代檔案與數位人文研究——以官方查辦民間教門為核心」計畫成員,於工作坊後合影。
近來聊天機器人ChatGPT全球爆紅,引發新一波人工智能(Artificial Intelligence, AI)運用風潮。由於人工智能的運作主要根基於知識推理(reasoning),其與知識本體之間的關係看似遙遠,實則深具緊密性。
美國雪城大學(Syracuse University)資訊學院教授秦健(Jian Qin)3月下旬於中央研究院展開知識組織系列講座時,點出知識本體與人工智能之關聯性。
秦健為美國伊利諾大學香檳分校(University of Illinois at Urbana-Champaign)圖書資訊學博士,研究範疇聚焦於後設資料、知識組織與知識本體建構設計、研究資料管理、科技傳播學等,合著有《後設資料》(Metadata)一書。其研究項目先後受到美國國家科學基金會(National Science Foundation, NSF)、美國國家衛生研究院(National Institutes of Health, NIH)等機構的資助,曾獲2020年Frederick G. Kilgour圖書館與資訊技術研究獎(Frederick G. Kilgour Award for Research in Library and Information Technology)。
有感於圖書資訊在數位人文研究中扮演著整合領域知識與技術運作的橋樑角色,本中心特邀國際知名學者秦健赴臺,於中研院駐點一週。期間她不僅主講3場知識組織系列講座,以深入淺出的方式,對知識本體的理念定義、架構設計、實務應用等提供了完整的概念傳遞,更參與工作坊,進一步對本中心發展中的知識本體計畫,予以見解及建議。
3月27日上午,秦健以「本體論的基本原理」(Fundamental Principles on Ontology)為題,鉅細靡遺闡述知識本體的起源、發展運用及其對數位人文研究之輔助。從何為知識本體、現今被廣泛採用的知識本體類型範例、知識本體架構組成元素,乃至實作上實體管理(entity management)等知識本體建置基本議題,她皆知無不言,為聽眾上了一堂紮實的基礎課。
構建知識架構 助深度探索研究資料
知識本體(ontology)一詞,源自於哲學中有關事物(beings)存在之因,關鍵點在於如何系統化分類這些存在的事物。在知識組織領域,知識本體被認為是一種正式的模型,主要用於表述某領域中的知識,而類別(class)、屬性(property)與推理規則(axiom)是三個必不可缺的元素。
秦健指出,建置知識本體即為構建知識架構,在實作上,可將領域知識、概念詞彙藉由一種標準,規範、形塑為一個使知識可重複展現、可驗證的工作流程。換言之,知識本體通過組織檔案資料中的知識,對檔案資料進行標註、整理、管理、分類、歸類及鏈結,藉此定義實體(entity)間的關係,並使機器針對實體進行自動編碼(codify)。
她強調,知識本體是一個規範的概念模型,故需以程式語言如JSON、RDF、XML等將其結構化,最終要能為機器所用。如此一來,其才能透過演算法,甚至人工智能的方法為我們所用,提供讀者及學者深度的探索功能。「不只是探索材料,而是探索知識。」
Friend-of-a-Friend(FOAF)、Schema.org與CIDOC CRM,是如今被廣泛採用的3個知識本體範本。「轉型中的海上生活」(Seafaring Life in Transition,簡稱SeaLiT)即應用了CIDOC CRM,呈現1850至1920年代世紀交替時間段中海上生活的資訊,檔案資料包括手寫的、使用不同語言的船員名單、出船日誌、會計帳本、統計數據、工資單等。這些資料對研究極為有用,有助探討海上的勞工市場、海上及岸上的生活、貿易線路、航海模式,以及船老闆、船員、船長與當地的各種關係等議題。
「轉型中的海上生活」設立了SeaLiT Ontology,共確立46個類別、79個屬性等,作為模板化查詢的基礎。她表示,學者的能力和精力有限,此知識本體將相關的船、人等全部展現於一知識圖譜(knowledge graph)中,使用者可節省一步一步手工查找、整理、歸類檔案資料等步驟,學者有更多時間思考研究方面的問題,而非思考資料組織整理方面的問題。
提供思路框架 可依領域知識分析進行優化
一個標準化的知識結構,有助建立可重複使用的工作流程(repeatable workflow)。未來處理新的資料時,可回頭檢視此工作流程有哪些部分可供再利用。譬如,一旦將「人」的描述標準化,無論清代秘密宗教或明清文學方面關於人的描述,即可以相同標準化結構進行,從而避免不必要的重複發明。
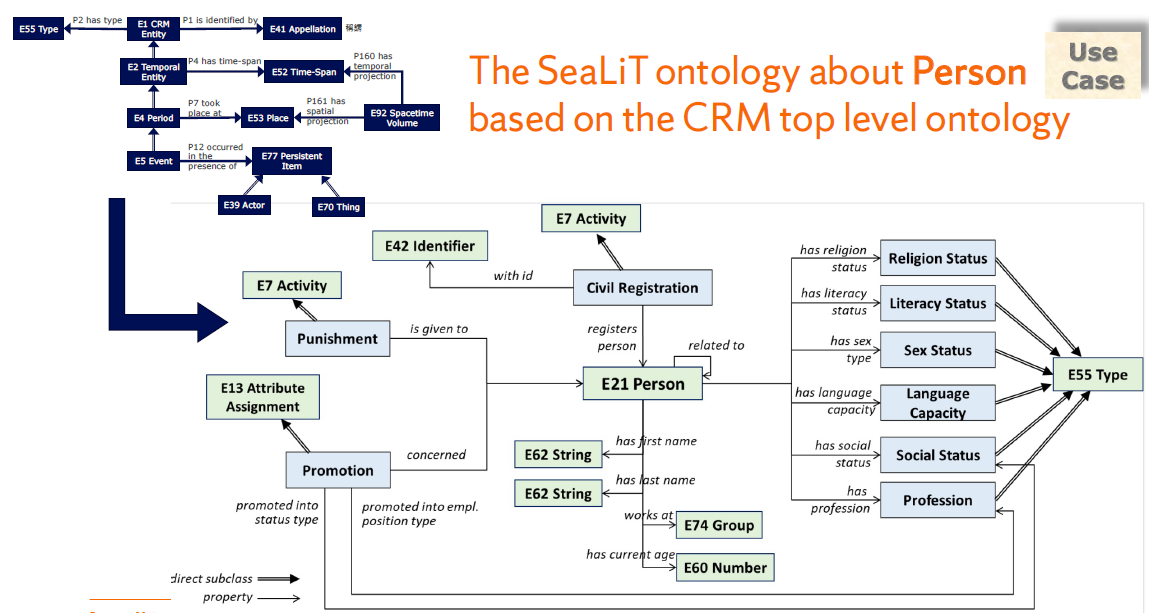
SeaLiT Ontology本體設計中,關於 「人」的描述。(圖片提供/秦健)
「建置知識本體無需白手起家,實際上可從不同的知識本體中,抽取有用的東西,將其整合成一個適用的知識本體。」
秦健認為,知識本體提供的是一種框架、思路,要將其變得更好用、更適用於自身領域,使用者需進行領域知識的深度分析(domain analysis)。
知識推理助攻 人工智能運作關鍵
人工智能的發展充滿各種可能性,前景無限。秦健表示,人工智能的根基在於知識推理,而推理的運作首要需將知識進行剖析,再予以機器編碼,才能達成人工智能的實踐。
她進一步指出,知識本體設計形成的知識分類構造,可作為提供機器讀取的框架(framework),以進行資料抓取、檢索。因此,知識本體與人工智能之間看似遙遠,實則有相通之處。
步步解析 知識本體打造重點
3月27日下午,秦健在第二場專題講座中,開講本體論的設計方法(Methods for Designing an Ontological Model)。透過近年推動的「線上需求經濟社群領域知識本體設計」(A Community Ontology for the Emerging On-Demand Economy Domain)、「鏈結檔案計畫」(The Linked Archive Project)等實作案例,她對於如何將知識本體的理論概念,轉化為資訊管理中可實際執行運用的步驟,進行深入說明。
在知識本體建構設計上,確定知識本體的描述範疇及主要概念詞彙、再利用領域內既有的詞彙分類概念資源、列舉本體設計中重要詞彙概念及概念間的關係、運用知識組織編輯工具轉換概念模型為具體的知識本體等,為過程中需格外思考的重點。
秦健提醒,將後設資料依據知識本體轉換為可達成資料交換、再利用的鏈結開放資源方面,在本體建模過程利用既有模型中的類別、屬性等語彙,針對類別實體進行整合與管理,並與外部資源鏈結加值,達成實體消歧異及豐富既有內容,則為另一要項。
此外,利用知識圖譜提升本體資料的可蒐性(searchability)與可發現性(discoverability),使研究資料轉換為使用者可直觀理解內容及意涵的呈現方式,是提升資料再利用的關鍵。
會中秦健亦以線上操作方式,展示Protégé知識本體編輯器、OpenRefine實體管理編輯器等數位人文工具,在知識本體建模設計,以及鏈結資料清理、調和與轉換上的實作應用。
開放資料晉身開放科學 形塑資料生態系統
隔天下午,秦健則赴國立臺灣大學圖書資訊學系,於本中心執行秘書陳淑君「數位典藏與數位策展」課堂上,從開放科學(Open Science)與開放資料(Open Data)的角度,解析圖檔領域的契機。
在此專題講座中,她基於過往實務研究工作經驗,展現以知識本體為基礎所建置之研究資料,如何進一步以「人」為出發點,提升為研究者與一般使用者均能受益的「開放科學」,而非僅是單純的「開放資料」。
她認為,在資料建置過程中,應掌握資料內容的透明性、可驗性、可批評性及可複製性等要點。資料提供者亦需對其資料內容負責,並提供所有潛在使用者同等的近用機會。如此,才算達成「開放科學」的基礎實踐原則。
而研究或調查資料在開放至資料儲存庫(data repositories)過程中,最好能導入「FAIR原則」(FAIR Principles),以便使用者能在單一資料庫中檢索、近用所有可能再利用的資料,無需到不同資料庫查找。如此亦能建構數據資料間的關聯性,創造「資料生態系統」(data ecosystem),並轉化資料庫為「知識網絡」(knowledge network)。
為實現此願景,未來在圖書館與檔案館資料典藏管理與研究上,秦健建議應以制度化、標準化、技術化方式,進行實體管理、資料集層級(collection level)後設資料建構等工作,使資料轉化為對社會整體更富再利用價值的「開放科學」。
參與工作坊 展開研究計畫交流分享
知識組織系列講座之外,秦健亦參與了2場工作坊。除了探討本中心計畫管理運用FAIR原則的可能,更針對現行「清代檔案與數位人文研究——以官方查辦民間教門為核心」計畫的發展現況,進行討論交流。
該計畫以清代秘密組織為題,運用清代史料,結合文字識別工具、關鍵詞彙知識本體之建構,進行跨組織、跨區域的長時段研究。計畫主持人陳淑君與計畫成員針對後設資料及權威檔欄位設計、語意型知識本體建模、資料清理轉置等規劃與成果,以及運用ChatGPT進行關鍵詞彙擷取及訓練過程等初探研究予以說明,展現計畫未來運用人工智能方式達成「人機協作」(human-machine collaboration)的可能性。
秦健對於人工智能未來在知識本體設計建構過程中,加速實施實體自動化編輯管理之功用,持續看好。會中除了提供知識組織設計建構的優化建議,她更具體示範如何利用OpenRefine工具進行資料清理,以提升實體內容正確性。
同時,她亦分享知識結點(knowledge node)與關係偵測(relation detection)在知識本體架構設計的重要性。她強調,思考如何借用資料概念分類方式建構語意模型,達成知識組織(knowledge organization)設計固然重要,惟強化抓取、創造或彙整概念實體間的各種關係,進行概念間的多元關係類型(relation types)規範,才是構成知識庫的重要方式。這也是目前人工智能輔助數位人文研究的核心,達成知識再現(knowledge representation)的目標。
長達一週的駐點之行,秦健為聽眾帶來紮實的知識組織基礎課程,亦與本中心進行深入交流,對知識組織開發與實務應用給予建言與指導。本中心召集人陳熙遠對此表示謝意,並期許往後展開更密切的合作。