報導/葉恩慈、房翠瑩
攝影/林郁靜


臉書粉絲的按讚行為,竟可「標誌」出「藍中之綠」、「綠中之藍」的臺灣立委,進而演算出樂團、運動等各類粉絲頁的藍綠指數?
中央研究院資訊科學研究所研究員陳昇瑋在3月29日舉辦的「資料科學往前看-從大數據到人工智慧」演講中,強調通過機器學習,能挖掘潛藏在大數據中不為人知的秘密,讓其應用呈現人工智慧,如此才算活用資料,充份發揮資料分析的價值。
大數據不只是巨量資料
近年來臺灣掀起「大數據」(Big Data)熱潮,惟大部份人把其誤認為「巨量資料」,他直言,這似乎流於狹隘。「其實,大數據(的特性)是三個V,除了資料量大(Volume),還包括速度快(Velocity)、多樣性高(Variety),只要符合其一即可。」
如今處於數位科技時代,臉書、Twitter、Line等當道,不僅資料的產生速度快,處理速度亦快,如電子商務即需分析「這一刻」的資料以即時應變。資料多樣性方面,尤其值得注意的是,資料分析的主體已漸從傳統的結構性資料如報表等,過渡至文字、照片、影像等非結構性資料。「譬如,全臺的7-11便利商店內,即有2支監視器在『追蹤』顧客上門後先從哪邊逛起、怎麼排隊,且大概可判斷出性別、年齡、表情是喜是驚等,以改善貨架的擺設。」
若運用得當,非結構性資料極具價值。然而,面對資訊科技潮流下驟生的此類新形態資料,大多公司顯得無措,不知如何下手。也是臺灣資料科學協會理事長的陳昇瑋指出,從資料中萃取知識,就好比淘金,絕非易事,但若有「好工具」,即可得其門而入。
機器學習導向人工智慧成果
「1000公斤的土壤,只要能淘出5公克黃金,就是金礦。」他進一步點出,機器學習(Machine Learning)可謂是讓大數據變身「金礦」的好工具。
這門備受全球關注的嶄新技術,指的是由人類寫程式,讓電腦具有判斷能力,從而自訂規則來分析資料。通過此處理方法,從大數據材料所萃取的資料應用,不僅具備電腦分析海量資料的長處,亦展現人工智慧(Artificial Intelligence)特質。
被視為資料科學領域最大挑戰的新形態非結構性資料,也能通過此路徑,淬煉出金沙。「只要你有註冊社群媒體、有按讚,我們就能從中看到一些東西,這是業界和做研究前所未有的機會。」
透過臉書專頁的粉絲按讚分析,演算出政治人物、粉絲本身乃至於所有粉絲頁的藍綠版圖,即為一例。陳昇瑋與中央研究院政治研究所副研究員張傳賢依據臺灣立委臉書專頁的粉絲重疊度,發現若干立委如王金平、林佳龍確有「藍中之綠」、「綠中之藍」現象(見圖一)。而從使用者追蹤了哪些立委的專頁,可歸納出其政治傾向;再據此分析他們的其他按讚專頁,即能演算出最藍、最綠的樂團及媒體等。「不過,有些標榜某某政治人物的臉書專頁,粉絲的藍綠傾向恰恰與該政治人物相反,如『我愛連勝文』專頁的粉絲就非常綠,這時就可向其提出警告。」
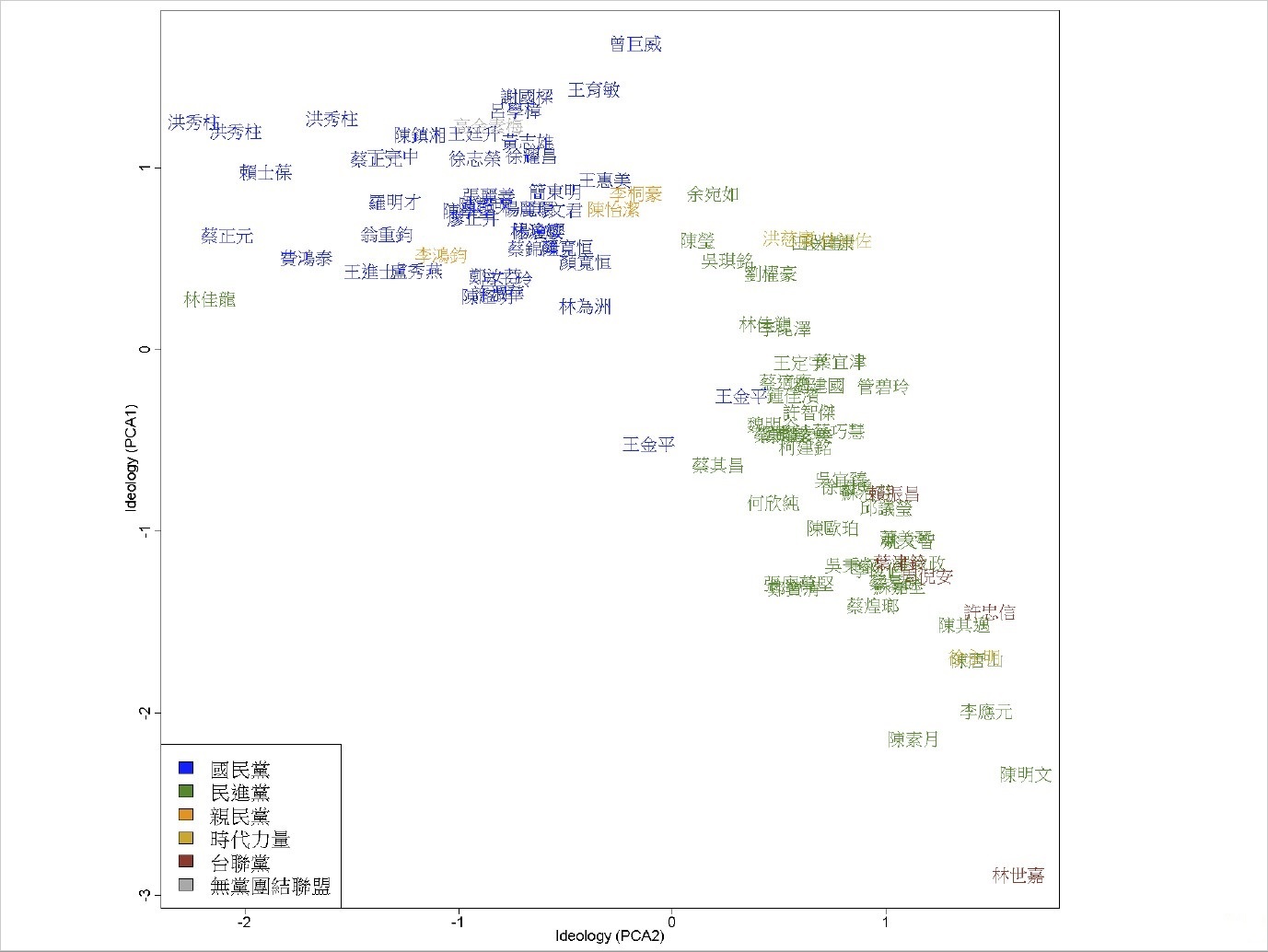
圖一
資料建模神預測
此外,近期研究亦發現,較常在Twitter使用負面字詞的使用者,心臟病死亡的機率較高。他強調,以Twitter用字進行的預測,準確度甚至大於傳統以吸菸、肥胖等為預測變項的調查(見圖二)。由此可見,社群媒體上的日常發文所潛藏的資訊不容小覷,通過機器學習進行探索、分析後,能進一步建立模型,預測人的行為或疾病發生機率。

圖二
此種以資料分析為本的預測模式,近年來開始被引入向來憑直覺與專業經驗行事的出版行業。陳昇瑋去年與博客來合作,探討讀者背景、生活型態與購書行為的關聯,將不同購書客群之間的「差異性」數據化,再依據書名關鍵字、商品特徵、上市前市場狀況等,預測書籍的暢銷指數。
「現在一本書要上架,可採取的模式是,請出版社提供10個書名、好幾張封面設計,讓電腦選出可能賣最好的。」他說,未來電腦甚至有望取代作者與出版社的角色,直接「產生」書名。這意味著資料分析已晉身「指示型」層級。
人工智慧的潛能無可限量,前提是要懂得善用資料分析,才能自資料砂礫中淘出金來。演講當天讓近百位觀眾驚呼連連的,是陳昇瑋的獨門資料淘金術。
