報導/闕宇彤
攝影/林郁靜、林慧菁
客委會與政大團隊建置「客語語料庫」(預計2022年上線),保存瀕危語言。德國馬克斯.普朗克科學史研究所研究員陳詩沛向大家介紹「地方志研究工具集 LoGaRT」。中研院近史所博士後研究員葉韋君建立詞語的共現關係網絡,分析《婦女雜誌》中出現的詞彙,以婦女作為田野調查的對象。陳冠霖講解清理《朝鮮王朝實錄》資料的經驗。本中心研究助技師王祥安、專案經理李祐陞分享建置「中研院數位人文研究平台」的一手經驗。黃志揚將自然語言處理的技術應用於公司行號的法律判決書,結合公司營運狀況,找出公司倒閉風險與法律判決書之間的關聯。阮家慶利用史丹佛剖析器(Stanford Parser)替多位譯者的風格進行分析,期望未來唐詩的風格分析得以自動化進行。
過去學者在編纂類書、地方志時,它們的組織結構,和現在的資料庫結構其實非常類似,透過重新組織資料,來達成特定目的。無論過去或現在,如何從文本摘取資訊,並以新的方法分群、類聚、比對、計量,是人文學者永遠的課題。
然而,在數位時代,資料累積的速度與處理的範圍,遠非傳統研究方式可比擬。人文學者如何因應數位時代的發展,使用數位工具而不役於數位工具?本文以「第十一屆數位典藏與數位人文國際研討會」(11th International Conference of Digital Archives and Digital Humanities, DADH 2020)中,數位工具、智慧資料對人文研究的促進,乃至方法上的轉變為切入視角,探究人文學者如何與數位協作。
不再是收藏資料的倉庫 資料庫變成課題本身
德國馬克斯・普朗克科學史研究所(Max Planck Institute for the History of Science, MPIWG)研究員陳詩沛在介紹「地方志研究工具集 LoGaRT」時強調,參與項目的人應對地方志有所了解。「『地方志研究工具集 LoGaRT』不是一個資料庫,而是一個研究課題。我們想了解它怎麼代表中國地方性?而它的發展,如何影響和怎麼形成當地的知識或者當地的認識。」
她提醒,在利用大數據進行大規模的歷史研究時,學者們不應天真地將不同來源、不同時段的所有數據都看成是平面的,相反地應考慮到中國的地方志和其他史料來源一樣,都是由不同的編纂者所編寫,且在中國也有所謂的「地方志學」。

馬克斯.普朗克科學史研究所團隊認為,資料庫的建置「使歷史學家能夠提出更大的問題,而這些問題不一定受地理區域、時間或個人努力的限制」。圖為「地方志研究工具集 LoGaRT」的網站頁面。(圖片來源/馬克斯.普朗克科學史研究所官方網頁)
當研究者使用新結構,把資料做成一個新的資料庫時,資料之於研究者便產生了新的意義。對研究人員來說,與其被動地把資料庫當成是獲取資訊的倉庫,不如將之視為「研究主旨」本身。資料庫有什麼欄位,以什麼結構組成,都和研究主旨有關。國立臺灣大學數位人文研究中心兼任博士後研究人員曹德啟在本次會議,便利用「DocuSky數位人文學術研究平台」中的「文本批次標記」工具,將各類詞彙標記於文本上,之後使用資料庫時,更能直指問題意識,讓文本的探究開展出更深向度。
俯瞰資料內容掌握全局 觀察資料結構補強細節
帶領馬克斯・普朗克科學史研究所的主任薛鳳(Dagmar Schäfer)嘗言,「科學負責嚴謹,史學貢獻細節」。通過俯視大數據,能對歷史事件、議題、某時間區段的某地,有更好的概觀;經過思考資料的形成、資料彼此的關聯,則能補強更多細節,避免誤讀。例如地方志此類資料,存世數量可觀、信度佳、每隔一段時間便會重修,跨越時地,可進行大規模的研究。不過,如同該研究所研究員林農堯在會前「CHMap工作坊:窺探清末民初的中國地理」中所提醒,「雖然資料庫的使用已十分常見,但大多數人仍是透過關鍵字搜尋,搜到的資料很可能是去原始脈絡的」。

CHMap地圖資料庫提供19世紀末20世紀初的中國土地調查地圖,使用者可將歷史地圖無縫納入任何GIS繪圖軟體。
人文學者應對資料庫的組成有更多掌握。在全球圖資界享有盛名的美國肯特州立大學資訊學院教授曾蕾(Marcia Lei Zeng),在專題演講「智慧數據 for 數位人文」中強調,人文研究的主要數據與既往「數字宇宙」項目不同,無法利用網絡爬蟲獲取,如何自特藏、檔案、口述歷史資料、年度報告等找到歷史性數據,是為挑戰。「學者也應注意,每筆歷史資料都有其產生背景,數據的結構、關聯,定義了整套資料的內容。」
美國肯特州立大學電腦資訊學院教授曾蕾在「智慧資料 for 數位人文」專題演講中,強調人文歷史數據十分難以獲取。
1+1=∞ 結構、鏈結帶來的整合與加值
曾蕾在刻劃大數據特徵時,以「數據如同原油」(Big Data is like Crude Oil)為比擬,需經提煉、加工才能產生價值。而大數據資料的資料特質,可由多個V開頭的單字說明,包括「規模」(Volume)、「速度」(Velocity)、「類型多樣性」(Variety)、「易變性」(Variability)、「真實性」(Veracity)等。當中最為重要的,是藉由清理、轉換才能獲取資料的「價值」(Value),大數據帶來的巨大價值。
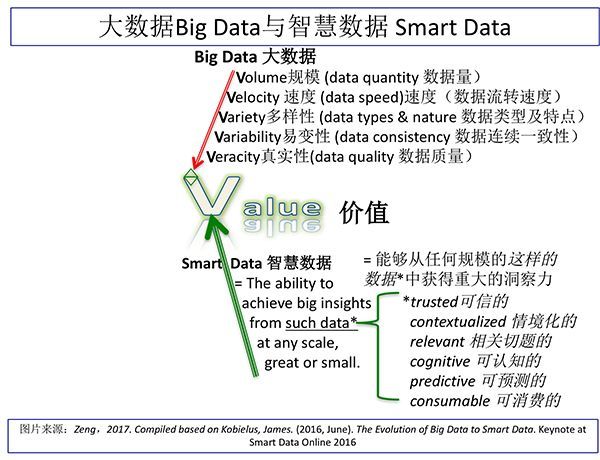
藉由清理、轉換才能獲取資料的「價值」(Value)。(圖片提供/曾蕾)
這些大數據透過對各學科領域之觀察,從文本分析、情境計算、人工智慧、自然語言處理、機器學習等,變得越來越智慧,透過清理、結構化,「提煉」之後,便成為可用的「智慧資料」。於此同時,大數據通過連結,也變得更大。越來越大,越來越智慧,便是智慧資料的未來。
而鏈結開放資料(Linked Open Data, LOD),則是將開放授權的資料拆解成可供機器讀取的語意資料。其結構化、標準化、脈絡化的特點,能適用於不同研究情境。也得益於LOD資料發布後任何人都能自由下載、重新使用、散布,繼而產生新的數據、訊息,注入源頭活水,知識變得更加循環。曾蕾以「羅馬帝國在線硬幣」(Online Coins of the Roman Empire, OCRE)、德國國家經濟資訊中心ZBW的「20世紀新聞檔案」 Wikidata項目(The 20th Century Press Archives,PM20)、芬蘭「Sampo」模型和一系列語義埠為例,說明智慧數據與LOD如何對各類資源進行數據整合和加值,在大規模的數據知識庫集成創建後,又如何展現國家級數位人文知識庫的架構。
同樣分享了「整合」平台、應用程式介面的還有馬克斯.普朗克科學史研究所團隊、威斯康辛大學密爾沃基分校團隊。在「RISE & SHINE:針對開發人員,介紹文本資源互通機制」工作坊中,馬克斯.普朗克科學史研究所團隊說明了RISE平台(Research Infrastructure for the Study of Eurasia)、SHINE應用程式介面(Application Programming Interface, API)的開發主旨:RISE平台涵蓋CBETA中華電子佛典和Kanripo漢籍,並與文本研究工具DocuSky和MARKUS合作,是傳播人文研究資源、分析數據的開創性平台。該平台可通過一組稱為SHINE的應用程式介面接口,與第三方研究工具與各種第三方文本集安全連接。
威斯康辛大學密爾沃基分校團隊則在"Relationships between Chinese Persons and Information Resources for Linked Data"論文發表中,介紹了上海圖書館使用鏈結資料的成功案例。上海圖書館將圖書館常見編目「機讀編目格式」(MAchine-Readable Cataloging , MARC),轉換為語意結構的鏈結資料(Linked Data, LD),一舉結合了圖書資源和人物傳記,甚至修正了西方知識體下圖書編目造成的,中文圖書和實體關係的偏誤。
馬克斯.普朗克科學史研究所團隊所分享的RISE平台,涵蓋CBETA中華電子佛典和Kanripo漢籍。(圖片來源/RISE平台官方網頁)威斯康辛大學密爾沃基分校團隊以「林徽因」作為圖書館轉換書目為語意結構的鏈結資料(Linked Data, LD)的例證。(圖片來源/ Proceedings of the Association for Information Science and Technology論文集)
透過鏈結、結構化,智慧資料與LOD能整合、加值數據資料,打破以往知識結構所帶來的窠臼。透過開放,塵封於角落的資料集更能發揮長尾效應,成為破解研究難題的鑰匙。
高連結、可擴充 DocuSky的最大優勢
DocuSky由國立臺灣大學資訊工程學系暨研究所特聘教授兼數位人文研究中心主任項潔所主持,學者可利用平台提供的雲端資料庫、各種工具,進行個人文本的格式轉換、標記、建庫、資料視覺化、地理資訊系統(Geographic Information System, GIS)整合等,是為學者量身打造的個人化平台。本次會議中,陳冠霖、曹德啟2位學者分別利用此平台,針對《朝鮮王朝實錄》、《洛陽伽藍記》進行探勘與實作。
從曹德啟使用DocuSky的經驗來看,該平台與維基文庫連結,無需從頭匯入文本,關鍵字搜索亦可連回維基,並透過WIKI Source找出相關文本,顯然是研究文本的一大助力。研究者在使用古籍文本半自動標記平台MARKUS自動標記人名時,還會自「中國歷代人物傳記資料庫」(China Biographical Database, CBDB)等匯入資料,亦可在Google Map上將歷史地名與今日的歷史遺址連結。會上曹德啟不時與工程師賴思頻討論未來的執行細節,也讓人感受到研究人員和工程師順暢溝通,是數位人文研究成功的最大推動力。

臺大數位人文研究中心兼任博士後研究人員曹德啟利用DocuSky的文本工具,對《洛陽伽藍記》進行探勘與實作。
《朝鮮王朝實錄》記載朝鮮王朝25代君主長達472年的歷史,相當於中國明清二朝,實錄內不僅詳載歷史事件,還記有大量外國與異族資料,為韓國國寶和聯合國世界遺產。韓國國史編篡委員會將其電子化為XML格式,在網站上公開漢文原本與韓文譯本後,陳冠霖將資料清理為DocuXml,用DocuSky完成後分類,並利用DocuXML的擴充性,新增數個標籤。此次實作,無疑為往後XML轉換DocuXML指明方向,明確指出DocuXml的可擴充性。未來DocuSky將能更貼合研究人員的使用需求,進行更深度的文本研究。
階層文本、詞間距 中研院數位人文研究平台提供細緻文本索引
中研院數位人文研究平台以其巨量的文本資料著稱,含括中研院歷史語言研究所「漢籍電子文獻資料庫」全文3億字、臺灣史研究所《臺灣文獻叢刊》3,000萬字、近代史研究所《皇朝經世文編》2,500萬字,乃至CBETA 3.6億字、Ctext開放貢獻文本52億字等。
是故,同樣是為研究者量身訂做的數位人文研究平台,為妥善利用平台內多元、大量的數位文本與權威詞,中研院數位人文研究平台提供的是更細緻的文本索引服務。不僅具備完整文本上傳與展示介面,可清晰地列出卷、章、節的階層結構,使研究者更易掌握文本結構和脈絡,更允許使用者一次搜尋多組文字、比對出多部文本共同出現的文字,並能依據搜尋結果再過濾、再設定詞彙中間距離。平台亦搭載了CKIP、Jieba、Standford NLP三種中文斷詞工具,使用者能藉由詞性組合,判斷不同文本的風格特徵。例如,自「地方詞+普通名詞+普通名詞」與「副詞+介詞+普通名詞」的組合,將能辨析出《南齊書》與《北齊書》不同的寫作特性與基調。此外,提供多人協作、使用LOD,讓使用者在平台上加入註解,並將註解更與註記區隔,不會被視作詞頻分析內容,也是平台與眾不同之處。目前「中研院數位人文研究平台」已有658位註冊會員。
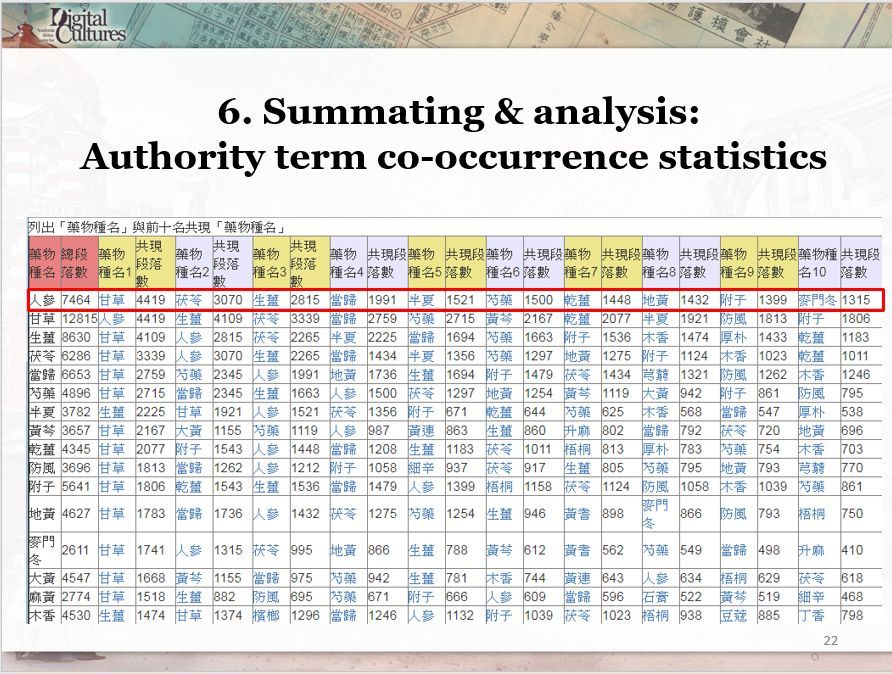
使用「中研院數位人文研究平台」做出的藥物共現詞分析。
由本院臺史所副研究員張隆志團隊帶來的論文〈數位人文學與臺灣地方菁英研究:以《臺中第一中學校建校捐款名簿》分析個案為例〉,便是使用「中研院數位人文研究平台」的文本自動標記、詞頻統計、共現詞分析、相似內容比對、社會網絡分析、地理資訊系統等功能,探討1913年至1915年間由林獻堂等人發起的臺中中學校建校寄附運動。研究發現,與林家往來較密切者為該街寄附人網絡的中心,呈現「阿罩霧林家—與林家關係較密者—街庄內其他仕紳」的網絡關係。
本院近史所研究員連玲玲團隊的〈以「婦女」為田野:《婦女雜誌》調查報導的詞語共現網絡分析〉,則以《婦女雜誌》為框限,依循詞語共現網絡(term co-occurrence network)分析,探索1930年代婦女使用詞彙、詞彙所構築主題、產生論述,甚至知識脈絡。該團隊先自《婦女雜誌》裡揀選出合適文章,建立語料庫,接著運用中文斷詞系統,並排除已停用之詞彙,歸結出共現詞網絡分布。從分析結果可知,學校與職場的共現詞群辨識度高,在學校中更傾向精神、信仰詞彙,職場則多描述勞動過程。在學校、職場、生產風俗、婚俗之外,其餘用以描述婦女生活的詞彙量少,但具有細微的區辨性,分別著重日常家務的詞彙(家務、家事、食物),啟蒙詞彙(壓迫、主義、智識、黑暗),以及女性的苦難(不幸、反抗)。

本院近史所研究員連玲玲(中)、博士後研究員葉韋君(左)發表論文〈以「婦女」為田野:《婦女雜誌》調查報導的詞語共現網絡分析〉。右為本院臺史所副研究員兼副所長張隆志。
自詞彙著手到語料庫
詞彙是語言的最小單位。找出自然語言的規律,建立運算模型,便是「計量語言學」;讓電腦擁有理解人類語言的能力,斷詞、理解詞、分析句子,了解語法及語義,便是「自然語言處理」(Natural Language Processing, NLP)。語料庫則收錄龐大且具組織架構的語言,涵蓋文字、手語、聲音等,既是語言學的研究工具,更為語言學研究的重要成果。在本次會議裡,通過3篇論文發表,可了解數位人文工具在不同階段語言研究中,扮演何種不一樣的角色。

史丹佛剖析器(Stanford Parser)含括阿拉伯文,中文,英文,法文,德文和西班牙文多種語言。(圖片來源/Stanford Parser官方網頁)
阮家慶在〈應用史丹佛剖析器計算唐詩英譯文銜接結構相似性:一個計量語言學研究初探〉中,利用史丹佛剖析器(Stanford Parser),替唐詩英譯中多位譯者的風格進行分析,期望未來唐詩的風格分析得以自動化進行,並開發出集群分類分析的工具。黃志揚在〈基於法律判決書之公司倒閉風險預測〉中,將自然語言處理的技術應用於公司行號的法律判決書,並結合公司營運狀況,建立模型,找出公司倒閉風險與法律判決書之間的關聯。國立政治大學團隊的〈臺灣客語語料庫建置與初步資料分析〉,則通過收錄逾500萬字書面語料、逾10萬字口語語料的「客語語料庫」(預計2022上線),細緻地分析庫內10大高頻詞,歸結出結構助詞在客語中的重要地位。
破除本位主義 觀察群眾閱覽、引用行為
會中也有不少發表者觀察使用者的資訊行為,了解群眾使用資料庫、閱覽網站的習慣,進而提升所建置的平台,如北京大學、哈佛大學與本中心帶來的〈面向使用者需求的CBDB 線上查詢系統設計與實現〉、國立臺灣師範大學團隊的〈台灣歷史人物資料庫之知識本體建構〉、政大團隊的〈數位人文研究平台之階層式主題分析工具發展與應用〉,以及臺大團隊的「一個數位人文內容研究的文本擷詞工具」。
北京大學、哈佛大學與本中心通過分析用戶需求,重新構建了CBDB線上查詢系統。
北京大學、哈佛大學與本中心通過分析用戶需求,重新構建了CBDB線上查詢系統,使新系統在功能上具備資料載入、匯出功能,符合使用者利用其他工具、軟體進一步分析資料的需求。臺師大團隊論及升級「臺灣歷史人物傳統資料庫」(Taiwan Biographical Database, TBDB)時,也強調與外部標準建立交換機制,或希望能架構於上,透過現有機制與其它系統交流。而政大團隊透過觀察平台裡有╱無階層式主題的使用者經驗,歸結出具階層式主題的「羅家倫先生文存數位人文平台」能輔助讀者於短時間內掌握主題脈絡。與項潔共同創設DocuSky的杜協昌,則以改良夾詞工具,推出新版「擷詞工具2020」為發表主軸,並用具中文與西文拼音、豐富詞彙類別的《熱蘭遮城日誌》為示範資料。他不但在新版工具中擴展了詞夾子的功能,允許使用者運用類似前後綴詞的方式來捕捉詞彙,更讓使用者載入巨集、使用指定異體字集。
會中亦有發表人雖未以平台作為討論主軸,卻透過觀察使用者閱讀、引用文本的行為進行分析,仍能向相關從業者提出建言。〈檔案相關新聞文本探勘及其情感認知分析〉論文發表團隊藉分析新聞報導中的輿論內容、社會大眾對於檔案議題的看法與認知,冀能提供檔案主管機關推動檔案素養教育、改善國家檔案開放應用政策時若干參考。
「與研究主旨更貼合」、「整合性更高」、「面向使用者需求」,似乎是4天會議下來,許多團隊最常提出的數位工具、數位平台調整方向。也許數位時代的人文研究和過去相比,最為不同的是與各學科領域更頻繁地溝通,與外界對話,打破學科藩籬。一方面,人文研究的抽象知識概念和其它領域的知識概念可以重合、交流,另一方面,人文學者也可藉此重新探查人文知識和其它知識領域的不同。一如資訊學界的「知識本體論」,便對人文學界的研究很有幫助。
塔勒布(Nassim Nicholas Taleb)在《黑天鵝》一書中,曾提出「反圖書館」(antilibrary)的概念。長期將自己圍繞在大量尚未閱讀的書籍中,是一種持續提醒自己知識有限的方式。這些未讀的書組成的就是「反圖書館」。在面對智慧資料、數位研究工具時,人文學者們不妨也抱持「反圖書館」的心情。時時與外界對話,了解數位工具的原理、智慧資料的結構,揣想知識的邊界。
延伸閱讀:
【DADH 2020系列報導一】回首臺灣數位人文之路 展望未來新可能
【DADH 2020系列報導三】掌握研究問題意識 釋放資料潛力
【DADH 2020系列報導四】學術可以很生活 數位人文研究繽紛多元